
Update as of januari 31st
Seems like Dell fixed their repository and vLCM can now download the VIBs again as it should when adding a VIB to an image.
Here is the original article I wrote
We have been using the Dell depot in vLCM for a while but since a couple of days we see issues when we try to include some VIBs in an image. Including in the image works, but as soon as we try to remediate a host, vCenter try to download the VIB but that fails and thus remediating the host fails.
We added the Dell repository to our vCLM config:

Next thing we do is add a VIB from this repository to the image we will apply to our cluster:

But when we try to remediate the cluster, it tries to fetch the VIB from the Dell repo but fails …

It seems like the VIB that needs to be downloaded is not available at the URL vCLM gets from the Dell repository ….
I am able to access https://vmwaredepot.dell.com from my vCenter Appliance but trying to fetch the VIB gives me a 404 error: (In this screenshot a proxy is used, but even with a direct connection it fails)
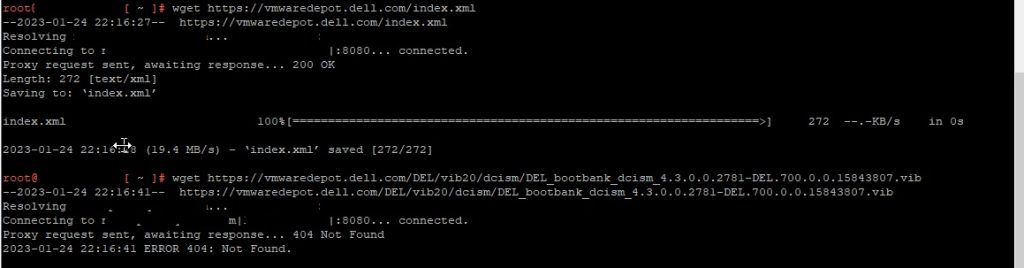
Seems to me like Dell changed the directory structure on https://vmwaredepot.dell.com but forgot to update the xml index file ….. Getting in touch with Dell to get this fixed, will update this article when I get more info.



